Artikulli i botuar në Science” (Language trees with sampled ancestors support a hybrid model for the origin of Indo-European languages), ku parashtrohet një model i prejardhjes së gjuhëve indo-europiane ka ngjallur interes të madh në publik, të paktën mes shqiptarëve.
Autorët e atij studimi shpjegojnë se kanë përdorur “modelet e inferencës filogjenetike bayesiane” për të analizuar një dataset të ri të zgjeruar dhe të korrigjuar të leksikut themelor (core vocabulary) të 161 gjuhëve indo-europiane, të organizuar sipas bashkëpërkimeve (shared word origins) për të testuar supozimet e zanafillës së drejtpërdrejtë.
Modelet filogjenetike tregojnë marrëdhëniet evolucionare midis specieve të ndryshme biologjike ose entiteteve të tjera në bazë të ngjashmërive dhe të diferencave në karakteristikat e tyre fizike ose gjenetike. Më i njohuri i këtyre modeleve është pema. Modelet janë përdorur kryesisht në biologji dhe në degë të përafërta (p.sh. në epidemiologji, për të analizuar transmetimin e sëmundjeve ngjitëse).
Lexoj se përdorimi i modeleve filogjenetike në studimin e historisë evolucionare të një familjeje gjuhësore nuk është vetvetiu i përligjur: gjuhët nuk janë qenie të gjalla dhe nuk evoluojnë si qenie të gjalla. Për këtë arsye thjesht metodologjike, modelet janë korrigjuar, plotësuar dhe përshtatur, për t’i shërbyer më mirë fushës së re të studimit.
Këtu më duhet të sqaroj se unë nuk i njoh modelet filogjenetike dhe as jam në gjendje t’i përdor dhe aq më pak të gjykoj efikasitetin e tyre.
Megjithatë, edhe sikur të pranojmë se këto modele janë përligjur tashmë, problem më vete përbën kompilimi i datasetit fillestar – ose i leksikut themelor për gjuhët e marra në shqyrtim. Në radhë të parë, sepse shumë gjuhëtarë nuk besojnë se ruajtjet dhe ndryshimet në leksikun “(core) themelor” mund të shërbejnë mirë për të gjurmuar historinë e një gjuhe dhe marrëdhëniet e saj me gjuhë të tjera të familjes. Tradicionalisht, për këtë qëllim, ndryshimet fonetike (fonologjike) dhe gramatikore (morfologji, sintaksë) gjykohen si më të besueshme. Në radhë të dytë, sepse vetë listat me fjalë të leksikut themelor nuk janë të përcaktuara mirë, shpesh varen nga zgjedhjet e këtij apo atij studiuesi, sikurse varen nga niveli ekzistues i njohjes për një gjuhë specifike a nga cilësia e këtij apo atij burimi; prandaj vihen rëndom në diskutim, nga gjuhëtarët.
Shqipja, veçanërisht, jo vetëm është e dokumentuar varfër si gjuhë indo-europiane, por edhe etimologjitë e leksikut shqip janë mjaft divergjente. Në qoftë se hartuesit e datasetit të shqipes janë nisur, të themi, nga Fjalori etimologjik i Orel-it, do të kenë hartuar një listë të ndryshme nga ajo që do të rezultonte po të mbështeteshin te Studimet Etimologjike të Çabejt ose te Fjalori i etimologjik i Topallit. Prandaj do të isha shumë kurioz të shihja datasetin e shqipes që kanë përdorur autorët e studimit, sa kohë që nga cilësia e këtij dataseti varen edhe përfundimet e artikullit, për kronologjinë e shkëputjes së (proto)shqipes nga familja e përbashkët indo-europiane dhe fillimi i shtegtimit të saj drejt Ballkanit.
(c) 2023 Peizazhe të fjalës™. Të gjitha të drejtat të rezervuara.
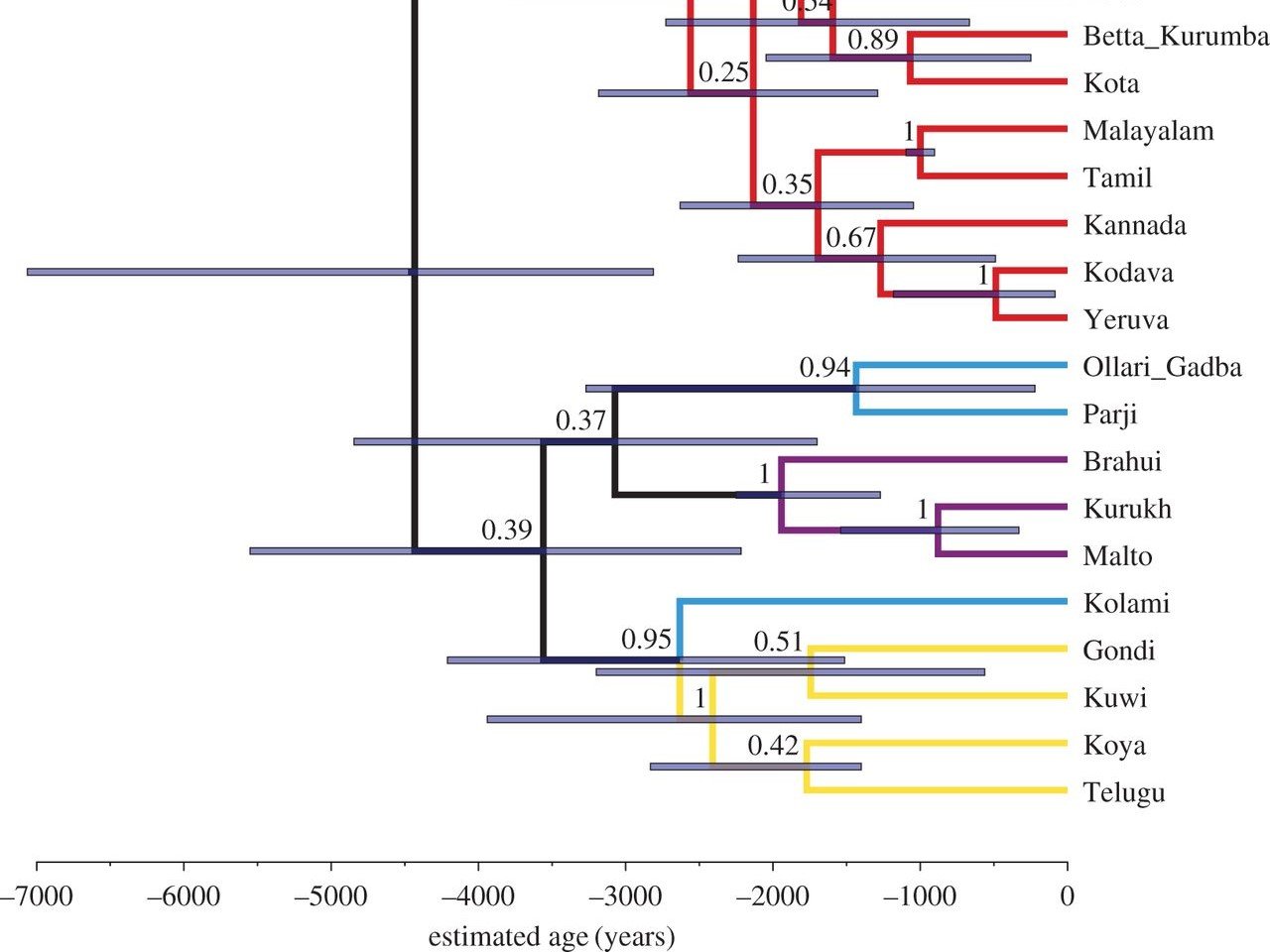
kopertina: pemë filogjenetike e familjes së gjuhëve dravidike (Indi).
Discover more from Peizazhe të fjalës
Subscribe to get the latest posts sent to your email.



Dataseti i kognateve https://iecor.clld.org/cognatesets?cladefilter=Albanian
Falemnderit!
I hodha një sy. Nuk arrij të kuptoj praninë aq masive të fjalëve arbërishte, shumica e tyre huazime kontakti nga dialektet e italishtes. M’u dukën edhe të paraqitura me gabime. Si mund të jenë këto pjesë e core vocabulary?
Mbase ma shpjegon ndokush…
Ndoshta machine learning ndonje dite mund te sqaroje se si ka qene gjuha ne nje periudhe per te cilen nuk ka te dhena duke u nisur nga ndryshimet e gjuhes ne periudhat per te cilat ka te dhena.
Me pelqen optimizmi juaj ndaj “machine learning” por nuk e besoj se ky eshte nje nga rastet ku ai/ajo mund te ndihmoje. Machine learning mbeshtetet ne “i njejti shkak sjell gjithnje te njejten pasoje”, por meqe “e njejta pasoje mund te vije nga shkaqe te ndryshme” machine learning mbetet e pafuqishme ne kete rast.
Nuk i dihet nese AI zbulon patern e ndryshimit te atyre qe njohim mund te ekstrapoloje ne reverse e te zbuloje si mund te kene qene ato qe s’njohim .
Jo, i dihet. Sic thashe AI nuk mund te shkoje ne reverse me siguri te plote, sepse edhe po te njohe patterns nuk mund te ekstrapoloje shkakun prej pasojes, me ate siguri qe ekstrapolon pasojen prej shkakut. Kjo nuk do te thote qe nuk mund te sajoje nje teori, e cila gjithesesi nuk mund te jete e sigurte 100%. Po te jap nje shembull. AI mund te njohe qe nje njeri qe goditet me plumb ne koke vdes, nje njeri qe ha nje thike ne zemer vdes, nje njeri qe e godasin me shkop bejsbolli disa here ne koke vdes, nje njeri me semundje terminale vdes etj kesi soji. Nga keto te dhena nqs si input AI i jepet “njenjeri vdiq” AI nuk mund te konkludoje shkakun e vdekjes. Mund te jape nje liste mundesish, por nuk mund te kete 100% siguri per te verteten.
Dule a nuk ka shqipja nje mekanizem te brendshem sipas te cilit transformohen tingujt rrokjet etj?
Edhe mund te kete (une nuk jam gjuhetar), por nqs ka, atehere perse duhet AI? Nqs ky mekanizem njihet a nuk do te mjaftonte Inteligjenca Natyrale e gjuhetareve per t’i zberthyer gjerat?
Shume gjera jane ende te panjohura Dule , plot me hamendesime e kundershti mes gjuhetareve.Prandaj dhe profesionistet e vertete perdorin shrpehjen “mendohet se ” , elifmatraket jane 1000% te sigurte ne deduksionet e tyre.Sado te mencem jene gjuhetaret nuk munden te krahasojne miliona fjale ne gjuhe te ndryshme ne ceshtje mintuash .teknologjia perparon shpejt e ben gjera qe deri dje dukeshin te pamundura.merr psh Google translate perkthimet e te ciles pak vjet me pare ishin primitive sot ne shume raste nuk dallohen nga ato te perkthyesve profesionale.
Alba nuk e kuptoj mire, kete diskutim e vazhdon nga naiviteti (me verte i beson ato qe po thua tashti) apo thjesht se do te besh konkluzionet. Une po mundohem te te ftilloj edhe nje here e pastaj bej si te duash:
-E para, sado kohe te kaloje me shume do te kete te panjohura se sa te njohura dhe te mencurit do te vazhdojne te fillojne diskurin e tyre me “mendohet se” etj. si keto. Se ç’bejne elifmatraket, me mire mos me u mare me ta.
-E dyta, qe teknologjia perparon me shpejtesi nuk po e mohon kush. Megjithate sado te perparoje teknologjia principet baze nuk ndryshojne. Fakti qe AI mund te beje me shpejt dicka qe njerezve u duhet me shume kohe nuk do te thote se AI e ben me mire dhe nuk me duket se ne kete pune ka ndonje fare ngutje. Per mendimin tim kjo pune do te vazhdoje edhe per shume kohe me “mendohet se” me AI apo pa AI, sepse ne fund te fundit qe ceshtja te quhet e zgjidhur perfundimisht duhet qe shumica dermuese e gjuhetareve serioze te bien dakord.
-E treta dhe e fundit, nuk besoj se ate punen e Google translate e ke seriozisht. Lexo pak me shume perkthimet qe behen me GT ne shtypin shqiptar dhe po nuk u shkule se qeshuri ne cdo dy tre fjali hajde me jep nje replike tjeter ketu(nuk besoj se ato perkthime i bejne njerezit se po te qe ashtu do te aplikoja me nje here per t’u shnderruar ne robot).
AI-driven tools and platforms can be used to analyze vast amounts of linguistic data, uncovering new insights into the structure, evolution, and diversity of languages.
If you can believe everything it is written….then do not forget the bible.
Per Alben:
Me poshte nje paragraf nga gazeta DITA, me gjase i perkthyer me google translate:
“Ndër karakteristikat e tjera, Rodiumi mund t’i rezistojë temperaturave të ujit dhe ajrit deri në 600 gradë Celsius dhe gjithashtu mund të mbetet i pazgjidhshëm në shumicën e acideve ekzistuese.”
Se si mund te arrije uji temperaturen 600 grade Celsius qe pastaj Rodiumi t’i rezistoje, dhe se si mbetet i “pazgjidhshem” ne shumicen e acideve egzistuese, nuk besoj se perben ndonje mrekulli perkthimi te AI.
Ja edhe linku per te gjithe artikullin:
https://gazetadita.al/ky-eshte-metali-me-i-vlefshem-dhe-me-i-shtrenjte-ne-planetin-toke-nuk-eshte-ari/